
Batch processing is the operational method of collecting transactions or records together and processing them as a group rather than individually in real time. In payment systems, this model is commonly used for high-volume recurring or routine transactions, where instructions are submitted, validated, and settled according to scheduled processing windows rather than instant execution. The Federal Reserve describes commercial ACH services as providing batched payment options for same-day and next-day settlement, and Nacha describes the ACH network as a batch, store-and-forward system.
In the financial crime environment, batch processing is important because it affects how risk is identified, when controls are applied, and how quickly an institution can intervene if suspicious or fraudulent activity is detected. Unlike real-time processing, batch-based environments often create a time gap between transaction initiation, file submission, validation, and settlement. That gap can be an operational advantage, because it may allow screening, reconciliation, exception review, and fraud checks before final processing. At the same time, it can also create challenges if firms rely too heavily on post-file review or if suspicious activity is embedded within large volumes of otherwise ordinary transactions. The same batch architecture that makes high-volume payments efficient can also make abusive patterns harder to isolate unless monitoring is designed around file-level, counterparty-level, and behavioral analysis. This is an inference drawn from the batch-oriented nature of ACH processing described by the Federal Reserve and Nacha.
From a professional financial crime perspective, batch processing should not be viewed as a neutral back-office mechanic. It is a control environment. Where transactions are processed in batches, the institution is often assessing not only individual payment instructions but also the integrity of the batch itself, the originator that submitted it, the timing of submission, the consistency of payment attributes, and any exception patterns within the file. This matters because some financial crime risks only become visible when transactions are reviewed collectively rather than one by one. A single payroll-like payment may appear unremarkable, but a batch containing unusual beneficiary clustering, repeated shared account details, abnormal value concentrations, or unexpected deviations from a customer’s historic file pattern may indicate fraud, mule activity, originator misuse, or laundering risk. This is an inference supported by the Federal Reserve’s description of batched electronic processing for large volumes of payments.
Batch processing is especially relevant in environments such as payroll, bill payment, recurring collections, vendor disbursements, government payments, and certain legacy or file-based payment operations. In these environments, the financial crime challenge is often less about a single anomalous payment and more about whether the batch as a whole is credible and consistent with expected activity. Institutions need to understand whether the originating customer, business, or intermediary has legitimate authority to submit the file, whether the file structure matches normal operational patterns, and whether the destination accounts, values, and timing align with the expected purpose of the payments. A compromised or abusive originator can use an apparently routine batch process to move suspicious funds at scale if these controls are weak. Nacha’s description of ACH as a system for both disbursements and collections illustrates why batch-originator risk is so important.
Watch on YouTube: Batch Processing
One of the central control issues in batch processing is that speed and scale can reduce visibility unless monitoring is designed appropriately. Large batch files can contain hundreds or thousands of entries, and operational teams may focus primarily on formatting, transmission success, and exception handling rather than deeper risk analysis. In the financial crime environment, that is not enough. File-based payment activity should be subject to controls around originator due diligence, expected-volume profiling, value thresholds, unusual counterparty patterns, return and rejection trends, and anomalies relative to prior batches. Where these controls are absent, batch processing can become a channel through which fraud, unauthorized debits, suspicious disbursements, or laundering-related pass-through activity is embedded within normal operational flows. This is an inference from the Federal Reserve’s and Nacha’s descriptions of batch payments being used for large-scale routine electronic movement of funds.
Batch processing also has implications for timing and intervention. Because batched systems are processed according to scheduled windows, firms may have more opportunity to identify suspicious activity before settlement than they would in a true instant-payments environment. That can strengthen pre-settlement controls if the institution uses the window effectively. However, if the review process is too superficial, heavily automated without effective escalation, or focused only on file acceptance rather than risk assessment, the institution may simply process suspicious transactions in bulk. In that sense, batch processing does not automatically improve financial crime control; it only creates the potential for additional review. Whether that potential is realized depends on governance, monitoring design, and operational discipline. This is an inference grounded in the batched settlement structure described by the Federal Reserve and Nacha.
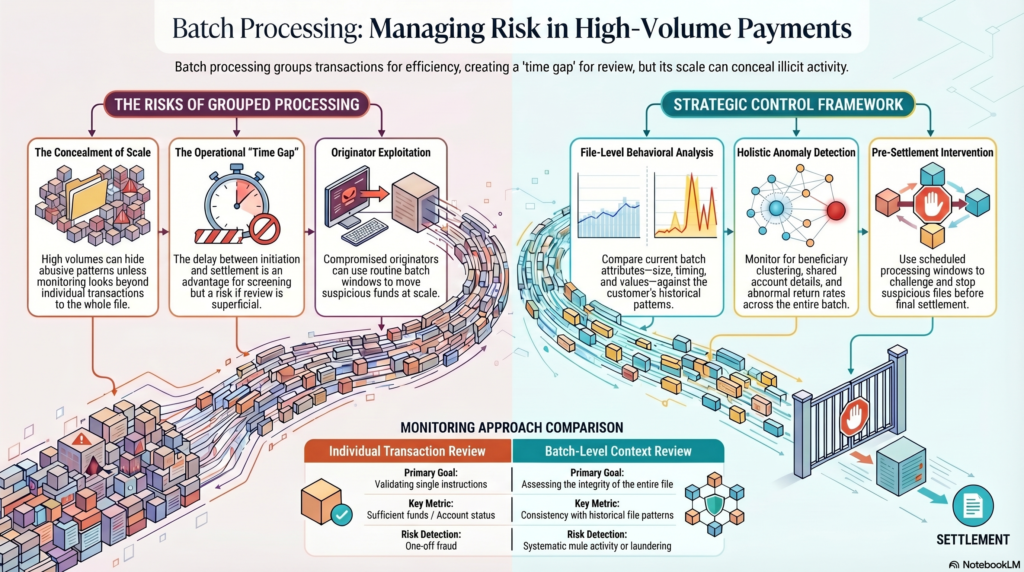
From an AML perspective, batch processing can complicate the analysis of customer behavior if institutions do not distinguish between normal file-based activity and suspicious structured movement. For example, repeated inbound or outbound batches involving unrelated parties, unusually rapid pass-through of batched credits, or sudden changes in the profile of submitted files may indicate that an account is being used in a way inconsistent with its stated purpose. In commercial banking, file-based payments are often entirely legitimate, so the challenge is not to treat batching itself as suspicious, but to understand whether the batching behavior aligns with the customer’s expected business model and historical conduct. This is a risk-based inference supported by the official descriptions of batch processing as a standard method for large-volume payments.
Fraud risk is equally important. Batch processing can be abused through compromised payroll files, manipulated beneficiary lists, unauthorized debit batches, synthetic vendor payments, or mass-originated transactions submitted after a control failure within the customer or institution. In these cases, the criminal advantage is scale. Rather than initiating one fraudulent transaction at a time, the attacker can attempt to move value through a full batch, knowing that routine operational handling may prioritize throughput over anomaly review. That is why strong controls over file submission, user access, dual approval, originator authentication, and pre-processing anomaly detection are critical in batch environments. This is an inference based on the use of batched processes for large-volume payment initiation and collection.
A mature financial crime framework therefore treats batch processing as a distinct monitoring context. The relevant question is not only whether individual transactions pass validation, but whether the batch itself is consistent with legitimate purpose, expected behavior, and authorized originator activity. Institutions should monitor for unusual file size, timing anomalies, beneficiary concentrations, abnormal return rates, duplicate patterns, altered payment narratives, and material shifts from prior batch behavior. They should also ensure that exception handling, reconciliation, and escalation processes are sufficiently strong to challenge suspicious files before settlement where possible. This is a professional inference drawn from the operational characteristics of batch payment systems described in the cited materials.
Ultimately, batch processing is a core operational concept in the financial crime environment because it shapes how large volumes of transactions are handled, reviewed, and settled. It supports efficient payment operations, but it also creates specific control risks where suspicious activity can be concealed within routine, high-volume files. In practice, effective batch-processing oversight requires more than technical file acceptance. It requires originator control, behavioral monitoring, anomaly detection, and governance strong enough to distinguish legitimate recurring activity from fraud, unauthorized transaction patterns, and suspicious movement of funds.



