A lexicon-based model is a rule-based detection model that uses a defined library of words, phrases, symbols, and related linguistic patterns to identify communications or records that may indicate misconduct or financial crime risk. In practice, these models are most commonly used in communications surveillance, where they scan email, chat, messaging platforms, and other digital channels for terms associated with insider dealing, market manipulation, off-channel communications, complaints, bribery, harassment, or other prohibited conduct. The FCA’s 2025 off-channel communications review refers to firms updating surveillance lexicons to capture emerging channels and even non-text content such as emojis, GIFs, voice notes, and video messages.
From a professional perspective, a lexicon-based model is the operational step beyond a simple lexicon. The lexicon is the vocabulary set; the model is the control logic that applies that vocabulary to data, flags potential issues, and routes results for review. In that sense, a lexicon-based model is a structured surveillance method rather than just a static keyword list. Industry surveillance material describes lexicon-based communications surveillance as a model that references keyword lists and flags words or phrases that could indicate risky or prohibited behavior.
In the financial crime environment, lexicon-based models matter because many serious risks first appear in languagerather than in transactions. Employees or counterparties may discuss confidential information, attempt to move conversations off approved channels, complain about controls, reference suspicious arrangements, or use coded terms before any visible misconduct occurs in payment, trading, or customer activity. That makes lexicon-based models especially relevant to eComms surveillance, market-abuse controls, complaints monitoring, and broader conduct-risk management. FINRA guidance on electronic communications supervision and complaint surveillance reflects this by emphasizing firms’ obligation to monitor communications content and by noting the use of complaint-related keyword lexicons.
Watch on YouTube: Lexicon-Based Model
A key strength of a lexicon-based model is scale. It allows firms to review very large volumes of unstructured communications in a targeted way, rather than relying on manual reading of everything. This is why lexicon models have long been a backbone of communications compliance programmes. At the same time, the main weakness of traditional lexicon-based models is context. A flagged word does not necessarily mean misconduct, and the same phrase may be harmless in one conversation and highly suspicious in another. Industry commentary on lexicon surveillance repeatedly notes that keyword-based approaches can generate high false-positive volumes and “keyword fatigue” if they are poorly calibrated.
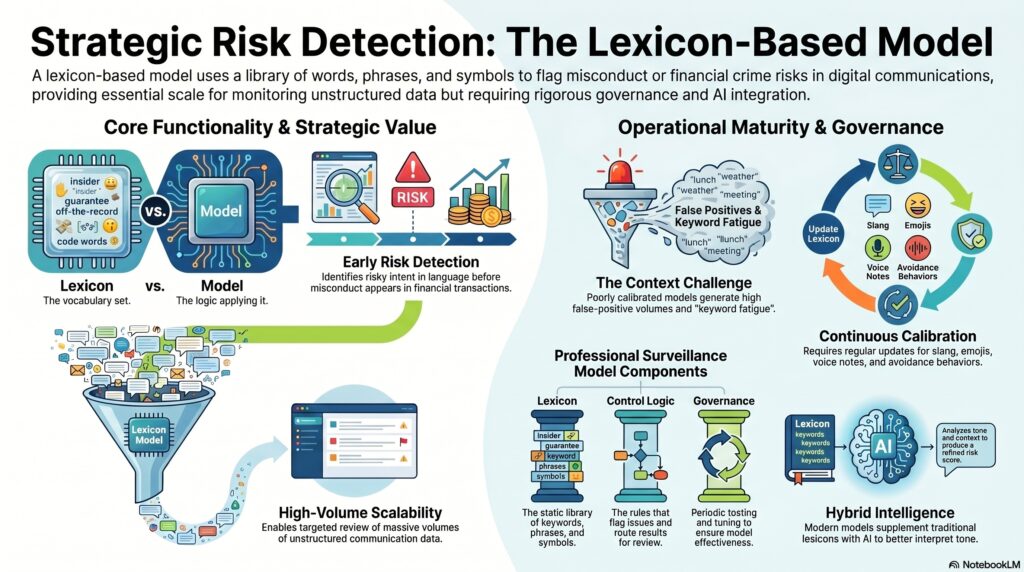
That is why governance and calibration are central. A mature lexicon-based model requires clear ownership, periodic testing, tuning, multilingual and channel-aware design, and regular updating as slang, abbreviations, emojis, or avoidance behaviors evolve. FCA findings on off-channel communications show that firms are expected to update surveillance lexicons as communication habits change. FINRA enforcement materials also show that firms can be criticized where lexicon-based communications surveillance is not adequately tested for effectiveness.
A professionally mature view also recognizes that lexicon-based models are increasingly being used alongside AI and contextual analytics rather than on their own. FINRA’s 2020 report on AI in the securities industry noted that firms were moving beyond traditional lexicon-based review toward more risk-based approaches that could better interpret tone, slang, or coded language. FCA and industry materials similarly suggest that lexicon-based surveillance remains important, but is being supplemented by smarter contextual tools rather than replaced outright.
Ultimately, a lexicon-based model is important in the financial crime environment because it provides a practical, scalable way to detect risk signals in communications and other unstructured data. Its value lies in turning language into a reviewable control output. But its effectiveness depends on calibration, testing, governance, and integration with broader surveillance and investigative processes. Used well, it is a core first-stage filtering tool; used badly, it becomes a noisy alert generator that weakens rather than strengthens the control framework.



